Problématique de l'optimisation dans une politique ressources humaines
Les collectivités et les entreprises sont tenues de comptabiliser
leurs émissions de CO2 liées à leurs activités et de planifier leur réduction.
L’outil utilisé s’appelle le bilan carbone et sa méthodologie consiste à
collecter de nombreuses données liées aux activités et convertir l’information
en tonnes de gaz à effet de serre émis sur une période donnée (année civile).
Aujourd’hui, la conduite automobile génère des émissions de CO2 qu’on estime
en France à 0,114 kg de CO2 par km parcourus avec une voiture à essence
(source : méthodologie du bilan carbone).
Si les évolutions des motorisations ont permis de
réduire les émissions de CO2 par km parcourus,
le comportement du conducteur permet d’économiser encore quelques litres de carburant :
on estime que l’adoption d’un comportement d’écoconduite permet d’économiser 7% de carburant par km parcouru.
Dès lors une collectivité ou une entreprise a tout intérêt à
former ses agents à l’écoconduite pour contribuer à la baisse de ses émissions de CO2.
Mais face au nombre important d’agents qu’il faut former, comment prioriser ?
Rendre obligatoire l’écoconduite à partir d’un seuil de km parcourus par an
L’idée de base est de former en priorité les agents qui roulent le plus.
Ceux-ci réservent des véhicules via un logiciel.
Le logiciel contient plusieurs tables, avec entre autres : :
Une table pour recenser les utilisateurs : user,
Une table pour recenser les véhicules : vehicle,
Une table de liaison pour chaque utilisation de chaque véhicule : user_vehicle,
Nous voulons un tableau où pour chaque utilisateur nous ayons la distance totale
parcourue en kilomètre par véhicule à essence, à gasoil et électrique.
Nous allons obtenir cette information via deux requêtes successives en utilisant postgreSQL :
Double jointure et création d'une vue :
CREATE VIEW user_fuel_vw
AS (SELECT user.name, vehicle.fuel, user_vehicle.distance
FROM user JOIN user_vehicle ON user.id=user_vehicle.user_id
JOIN vehicle ON user_vehicle.vehicle_id=vehicle.id
WHERE extract (year from user_vehicle.date)=2022) ;
Création d'un tableau croisé à partir de la vue :
SELECT *
FROM CROSSTAB (‘name’,’fuel’, SUM(‘distance’) FROM user_fuel_vw ORDER BY 1,2)
AS final_result (name VARCHAR(100), gas FLOAT, diesel FLOAT, electric FLOAT) ;
Les données sont ensuite exportées au format .csv pour être traitées avec Python.
En parallèle des données du logiciel de gestion de flotte de véhicules,
nous disposons du registre des agents ayant suivi la formation écoconduite en interne.
C’est une feuille excel. L’agent tenant ce registre a travaillé à normaliser
les prénoms et les noms pour qu’ils aient la même nomenclature que les noms et prénoms
de la base de données des déplacements professionnels.
Nous réalisons sur le registre des conducteurs une jointure à gauche avec le registre de l’écoconduite :
cela permet d’ajouter l’information selon laquelle les conducteurs ont suivi
ou non la formation écoconduite. Cette jointure est réalisée sur la clé de l’identité du conducteur.
Nous utilisons Python et la librairie pandas, notamment la fonction merge.
Maintenant nous allons modéliser le comportement du conducteur et son impact sur l’émission de CO2 :
Les Km se convertissent en litres de carburant ou en kWh électriques qui eux-mêmes se convertissent en kg de CO2.
Si le conducteur a suivi la formation écoconduite, alors nous considérons que les litres de carburant
ou les kWh électriques consommés sont inférieurs de 7% à la moyenne.
Conversion
Essence
Diesel
Electrique
L/km ou kWh/km
0,068
0,05
0,17
kgCO2/L ou kgCO2/kWh
1,68
2,87
0,079
Pour déterminer le seuil à partir duquel les agents devraient se former à l’écoconduite, nous ajoutons une information :
Si le nombre de km parcourus par l’agent est supérieur à ce seuil, alors nous considérons
qu’il a fait l’écoconduite et ses émissions de CO2 sont diminuées de 7% par rapport à la moyenne française.
Avec Python nous créons une fonction qui a pour variable le seuil de km annuel à
partir duquel l’écoconduite est obligatoire.
Elle a pour paramètre le registre des conducteurs et elle retourne comme valeurs
de sortie les émissions totales de CO2 dû aux déplacements et le nombre d’agents à former.
Le modèle tient compte des agents déjà formés.
Basiquement la fonction va diviser le registre de conducteurs en quatre groupes d’agents :
Ils n’ont pas fait la formation écoconduite au préalable et
leurs kms parcourus annuellement sont supérieurs au seuil,
donc nous considérons qu’ils vont faire la formation et
nous appliquons 7% de réduction sur leurs consommations de carburant et leurs émissions de CO2.
Ils ont fait la formation écoconduite au préalable et
leurs kms parcourus annuellement sont supérieurs aux seuils
mais nous appliquons quoiqu’il arrive les 7% de réduction sur les émissions de CO2.
Ils ont fait la formation écoconduite au préalable mais
ils ne roulent pas assez dans l’année.
Nous appliquons tout de même -7% pour leurs émissions de CO2.
Ils n’ont pas fait la formation écoconduite au préalable
mais ils ne roulent pas assez dans l’année.
Nous n'appliquons pas de réduction de -7% pour leurs émissions de CO2 liées aux déplacements.
def strategie_eco_conduite(data,seuil):
nb_eleve=0
nb_eco_sup_seuil=0
nb_eco_inf_seuil=0
#On divise la population en 4 : (eco/non eco) et (seuil). On note les groupes A,B,C et D
#On considère que si (non eco & >seuil) Alors ecoconduite => -7% consommation
#On calcule les litres ou kwh consommés
Nous faisons varier la valeur du seuil de 33 000km annuels (aucun agent ne devra se former)
à 0km (tous les agents devront se former) par palier de 500km.
Nous utilisons la librairie numpy.
#On exécute de multiples simulations X=[] #Pour stocker les résultats des simulations
for i in numpy.arange(0,33000,500):
x=strategie_eco_conduite(data,i)
X.append(x)
#Création d'un dataframe X=pandas.DataFrame(X,columns=["seuil","nb a former","nb sup seuil déjà formés","nb sous seuil deja forme","kgCO2"])
Dans la mesure où des agents sont déjà formés à l’écoconduite,
si tous les agents étaient formés, à nombre de km parcourus annuellement égal,
le potentiel total de réduction des émissions de CO2 est de -5,5%.
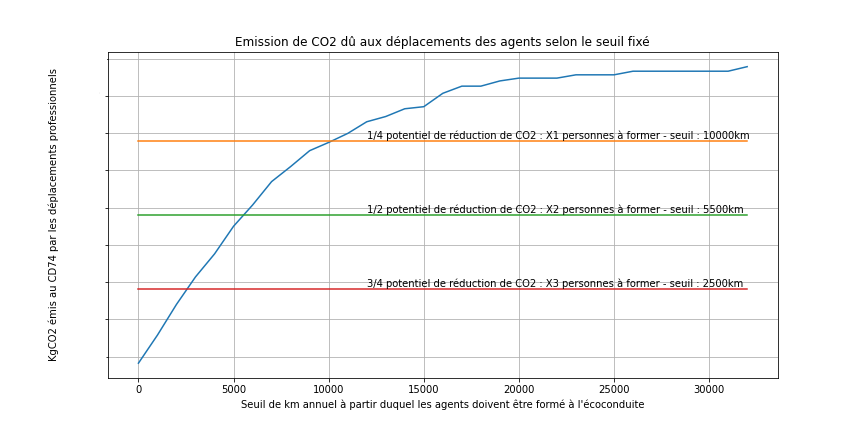
Figure A : Potentiel d'économie d'émission de CO2 selon le seuil de km retenu
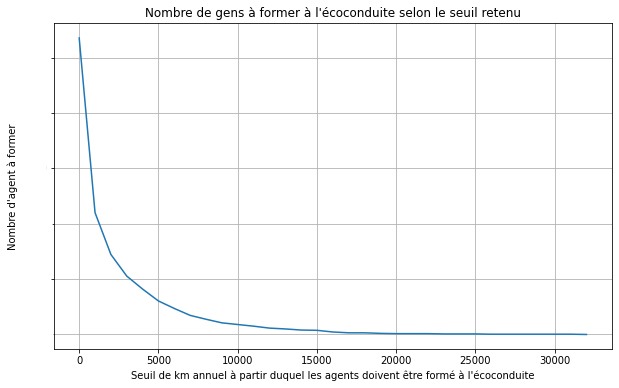
Le nombre d’agents à former selon le seuil retenu suit une exponentielle décroissante :
tant que le seuil est élevé, peu d’agents sont à former.
Nous avons vu également que peu d’agents réalisent le plus de km annuellement et le plus d’émissions de CO2.
Pour réduire les émissions de CO2 liés aux déplacements et
optimiser le nombre d’agents à former, un seuil à 2500km par an
nous parait opportun : X3 agents seront à former et
les émissions de CO2 spécifiques pourront baisser de 4,1%, soit les ¾ du potentiel total de baisse.
Figure B : Nombre d'agents à former selon le seuil de km retenu
Conclusion
Le type d’analyse que nous avons menée s’appelle une micro-simulation.
Notre base de données représente une population entière
(ici tous les agents qui ont utilisé un véhicule de service sur une année).
Pour chaque individu, nous simulons un comportement différent selon ses caractéristiques,
et plusieurs variables de sorties correspondent à l’impact du comportement.
L’agrégation finale des variables de sorties (ici par la somme) permet de voir l’impact global d’une politique.
La simulation permet de tester de multiples politiques.
Dans notre projet, la détermination du seuil km à retenir s’est faite à « dire d’expert ».
Nous aurions pu donner un prix à la tonne de CO2 évitée, aux litres de carburant économisés,
à la réduction des accidents et à l’augmentation de durée de vie des véhicules et
comparer ces gains avec le coût de la mobilisation des agents durant le temps de formation
(formateur et élèves). Mais évaluer certains gains aurait été vraiment complexe.
La micro-simulation peut être utilisée pour toutes données représentant une population exhaustive,
notamment dans les politiques sociales, en accidentologie routière, etc.