Création d'un module statistique pour le site web du Club Alpin d'Annecy
Problématique de la gestion des sorties et du reporting annuel
Le Club Alpin Français d’Annecy est une association membre de la
fédération des Clubs Alpins et de Montagne qui propose des sorties
sportives : ski de randonnée, escalade, canyoning, etc. Créé en 1874
comme section locale du Club Alpin Français, il est devenu localement
une véritable institution. Il est communément appelé le CAF.
Jusqu’en 2020, les inscriptions aux sorties (appelées collectives)
se faisaient au bar du club le vendredi soir dans une certaine confusion
(le club propose 1800 sorties par an pour 2600 membres).
Mais lors du premier confinement, deux membres du club, développeurs
dans leur vie civile, ont créé une application web pour permettre d’organiser les sorties.
J’ai rejoint l’équipe de développement pour développer un
module statistique. Le leader m’envoie 8 tableaux csv
sans plus d’explications et j’ai carte blanche.
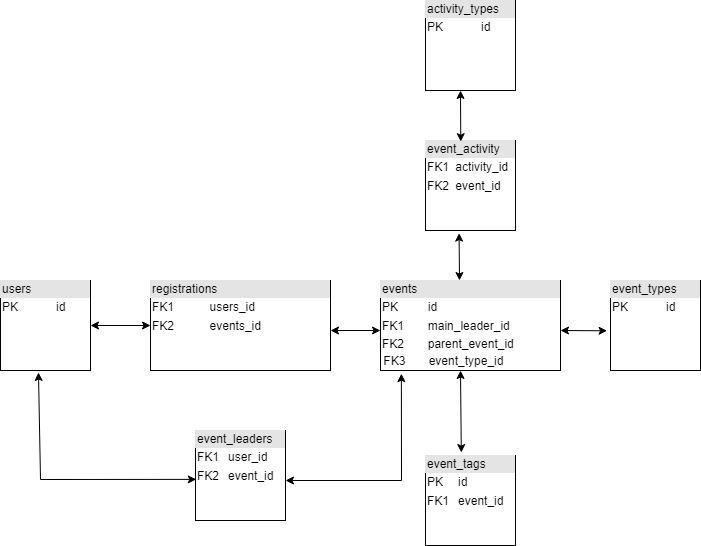
Schéma de la base de données
La base de données du Club est composée de deux tables principales :
- users qui répertorie les utilisateurs
- events qui regroupe les évènements
Une table de liaison dénommée
registrations fait le lien entre
les événements et les utilisateurs : c’est la table des inscriptions.
Un évènement est caractérisé par un type : sortie sportive (collective),
formation etc. Le créateur de la sortie ne peut assigner qu’un seul type
par évènement. La table
event_types liste les types d’évènements.
Un évènement peut en revanche comporter plusieurs activités (exemple :
ski de randonnée et snowboard de randonnée). Il existe une table de
type un-à-plusieurs nommée
event_activity_types et une table simple
nommée
activity_types qui décrit les activités proposées par le club.
Un évènement peut avoir un ou plusieurs tags qui spécifient des caractéristiques
supplémentaires, comme un évènement accessible sans voiture (mobilité douce) ou
handicap-friendly. La table
event_tags stocke cette information. Table de type 1-à plusieurs.
Enfin un évènement n’a qu’un seul leader principal mais il peut avoir des coleaders.
La table
event_leaders de type un-à-plusieurs recense l’ensemble des leaders d’un évènement.
Le tableau ci-dessous synthétise les tables.
| Nom des tables |
Types de table |
Usage |
| users |
registre |
Enregistrement de chaque utilisateur |
| events |
registre |
Enregistrement de chaque évènement |
| registrations |
table de liaison |
Isncriptions des membres du club aux sorties |
| event_leaders |
1- à plusieurs (formellement une table de liaison) |
L’ensemble des encadrants |
| event_tags |
1- à plusieurs |
Les tags (caractéristiques spécifiques) d’une sortie |
| event_types |
description |
Les 7 types d’évènements |
| event_activity_types |
1- à plusieurs (formellement une table de liaison) |
Les sports proposés dans chaque évènement |
| activity_types |
description |
Les 22 sports proposés par le club |
Création d'un module statistique pour le site web
A des fins de reporting, notamment pour les assemblées générales
ordinaires du club, le besoin d’un module statistique a été formulé.
Je me suis porté volontaire pour le développer. Je récupère dans les
procès-verbaux des assemblées précédentes le format qui est
actuellement produit : il me servira de guide.
Mon travail consistera à produire des fonctions pour
traiter les données et ces fonctions seront intégrées
sur le site par une autre équipe (celle qui maîtrise le côté développement web).
Mon angle d’attaque est le suivant : nous voulons faire des statistiques
sur les évènements organisés par le club. C’est donc la table events qui
va être analysée en profondeur. Mon code sera organisé en trois phases :
- Nettoyage des données
- Enrichissement de la table events
- Fonctions de filtrage et d’analyse
Mon code est visible dans le fichier script.py sur mon compte
git-hub.
Dans la suite je vais juste présenter les fonctions que
j’ai créées et mes choix de développement.
Nettoyage des données
Suppression des attributs superflus.
Remplacement dans la table event_tags des numéros par les noms des tags.
Création de la fonction extract_title pour nettoyer le titre des emoji présents le cas échéant.
Création d’une fonction pour extraire le secteur de la sortie : extract_location.
L’interface web invite le créateur d’une sortie à préciser le massif de la sortie.
Mais cette information n’est pas obligatoire et n’est pas stockée dans une colonne
de la table events. La description de l’évènement est stockée dans un champ description
qui contient tout le texte descriptif de la sortie. Nous avons créé une fonction qui repère
le mot « secteur » et à défaut le mot « lieu » car généralement le nom du massif suit
ces mots.
Création d’une fonction location_correction. Les fautes d’orthographe les
plus courantes sur les noms propres (par exemple beaufortin ou baufortain
pour Beaufortain) seront corrigées automatiquement.
Nous réalisons une fonction extract_duration pour calculer des
durées en journée (par palier de demi-journée) et
extract_age_gender pour créer à partir de la date de
naissance et du genre 6 classes de type âge-genre (exemple « Femme -25 »).
A l’avenir, il faudrait modifier la structure de la base de données
pour intégrer une colonne « secteur » et proposer une liste préétablie
mais pouvant être complétée. Il en est de même pour les titres des sorties
qui devraient être mieux normalisés, quitte à ajouter un champ libre sous-titre
pour les éventuels commentaires (par exemple « sortie annulable selon météo »).
Enfin, deux colonnes de plus seraient les bienvenues : une pour le nombre
de kilomètres et une pour le dénivelé.
Enrichissement de la table events
Cette partie du code est le cœur du script : nous allons
appliquer de nombreuses modifications sur le dataset events pour l’enrichir.
L’enrichissement de la table events se fait via la fonction upgrade_events
qui comporte 11 étapes que nous allons détailler :
- Step 1 : duration of activity
Nous appliquons extract_duration pour calculer la durée de l’activité
- Step 2 : registration status in count (active, canceled, no-show...)
La table registrations précise pour chaque évènement et chaque utilisateur
inscrit s’il est venu, s’il a annulé, s’il n’est pas venu sans se désinscrire etc.
A partir de la table registrations nous créons un tableau croisant évènement
et modalités de participation (en colonne). Nous ajoutons
ce tableau à la table event par jointure à gauche.
- Step 3 : age and gender class
Par une jointure de la table users sur la table registrations
nous ajoutons la date de naissance et le genre. Puis nous appliquons la
fonction extract_age_gender pour n’avoir qu’une variable qualitative
à 6 modalités (en colonne). Sur cette table registration améliorée nous réalisons
un tableau croisant les évènements et les 6 modalités âge-genre.
Nous ajoutons ce tableau à la table events par jointure à gauche.
- Step 4 : activity
Un évènement pouvant proposer plusieurs activités, la table de
liaison event_activity_types fournit un tableau croisant évènement
et type d’activité (en colonne). Ce tableau est injecté dans la table events par jointure.
- Step 5 : multi activity fusion
Dans la mesure où le reporting veut comptabiliser le nombre de sorties total et
le nombre de sorties par activité, il faudrait éviter le double compte.
En effet, une sortie ski de randonnée et snow de randonnée risque d’être comptée deux fois,
une fois pour chaque activité. Nous proposons de créer une nouvelle variable multi_activity
qui fusionne les activités présentes conjointement lors d’une même sortie.
- Step 6 : we specify if an event is a parent event
Il existe des évènements qui ont un parent : l’inscription à l’évènement
parent est un préalable. L’id de l’évènement parent est précisé.
Nous récupérons la liste des id d’évènement parents et
nous pouvons rajouter la colonne à variable booléenne « is_parent ».
- Step 7 : adding event type name
Dans la table events, la variable event_type_id est
remplacée par le nom des types d’évènements (relation 1-à-1).
- Step 8 : Correction bad event type assignation
Si un évènement est parent, il sert dans la pratique pour
« une inscription en ligne ». Si l’évènement est parent mais
n’est pas de ce type-là, nous réassignons le bon type.
- Step 9 : extract location
Nous utilisons la fonction extract_location sur le champ
description pour créer une nouvelle variable plus normalisée : le secteur de la sortie.
- Step 10 : coleader number
Dans la table, events, il y a déjà l’id de l’encadrant principal
de la sortie. Dans la table de liaison event_leaders, il y a les id de tous les
encadrants, principaux ou secondaires. Le script permet de discriminer le
nombre de leaders principaux et de coleader par sortie.
- Step 11 : add "mobilité douce" tag
A partir de la table event_tags, nous ajoutons l’information booléenne
qui spécifie si la sortie est à mobilité douce ou non (c’est pour le calcul du bilan carbone).
Finalement la fonction
upgrade_events a pour sortie une table
events enrichie de multiples colonnes.
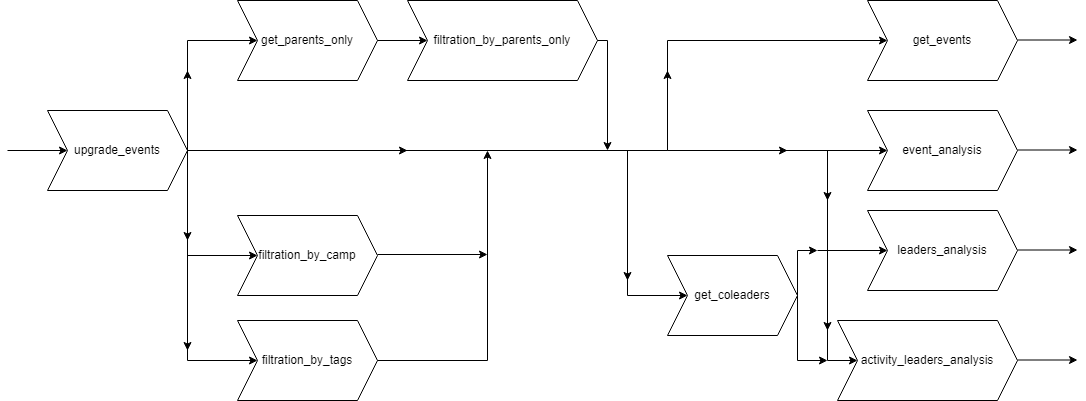
Fonctions de filtrage et d'analyse
Nous avons créé un certain nombre de fonctions pour réaliser des analyses courantes qui seront
directement réalisées sur le site par le biais de menus déroulants. Il y a des fonctions get
qui permettent d’obtenir une table, il y a les fonctions de filtration qui permettent des restrictions.
Il y a également des fonctions, dont le nom se termine par analysis, qui permettent de produire
des statistiques de type agrégation par type d’évènement et par activité.
Ces fonctions font la somme des éléments des colonnes :
- Nombre de jours
- Nombre de participants
- Nombre de sorties
- Nombre de femmes de moins de 18 ans
- Etc.
Les fonctions s’appliquent sur la table
events qui a été enrichie grâce à la fonction
upgrade_events. Elles renvoient toutes une nouvelle table en sortie. Soit
la table
events avec une restriction (filtration des données) soit
une table de valeurs agrégées par type et par activité.
get_events permet d’obtenir la table
events enrichie et projetée
sur les variables les plus pertinentes pour qu’un humain puisse rapidement analyser les données.
events_analysis est la fonction d’analyse des évènements du club.
Elle permet de faire des agrégations sur le type d’évènement et
le type d’activité. La fonction calcule à chaque fois le nombre de
sorties, de jours, de pratiquants et ce même nombre dans les 6 classes âge-genre.
Il y a un paramètre dans la fonction : simple ou double. Le premier utilise les
noms d’activités fusionnés que nous avons créés à l’étape 5 de la fonction
upgrade_events.
activity_leaders_analysis : cette fonction comptabilise pour chaque leader principal
le nombre de sorties encadrées, de jours, de participants par type d’évènement et par type d’activité.
Il y a encore une fois le paramètre simple vs double pour le dénombrement des activités.
leaders_analysis : est similaire à la fonction présentée ci-dessus mais elle
se limite au nombre d’évènements, de jours et de participants.
get_coleaders permet de modifier la table events en supprimant
les leaders principaux et en injectant pour chaque évènement les coleaders.
Nous utilisons une jointure interne sur les tables event_leaders et events.
Puis nous supprimons les lignes où apparaissent les leaders principaux.
Le résultat de cette fonction peut ensuite être injecté dans les fonctions
leaders_analysis ou
activity_leaders_analysis.
filtration_by_camp permet de filtrer la table events selon
les expressions types « camp d’été » ou « camp d’hiver » dans le titre des évènements.
Ce sont des évènements organisés sur plusieurs jours en un lieu précis.
Le résultat sera ensuite injectable dans les autres fonctions vues jusqu’à présent.
Cela permet d’analyser les évènements internes à ces séjours (il n’y a pas de création d’évènements parents lors des camps).
filtration_by_tags cette fonction permet de restreindre la table
events
aux évènements qui ont un tag spécifique. Là encore nous avons dû créer un tableau
croisant évènements et les modalités des tags, puis l’injecter dans la table events.
La filtration se fait pour un tag à la fois.
get_parents_only permet de récupérer les titres des évènements qui sont des évènements
de type parent. La fonction
filtration_by_parents_only filtre la table
events avec ce titre,
et nous pouvons appliquer les fonctions habituelles.
Cette fonction est très utile si nous voulons analyser l’ensemble des sorties
rattachées à un évènement parent, comme les sessions d’escalade
hebdomadaires qui demandent de s’inscrire en début d’année à l’évènement parent correspondant.
L’ordre d’utilisation des fonctions peut être déroutant, aussi le schéma ci-dessous représente les possibilités d’utilisation.